Context Engineering: Giving AI the Right Information at the Right Time
Context engineering is the practice of deciding what information an AI model sees at the moment it makes a decision, and how that information is selected, shaped, and ordered to fit inside a limited context window. If the agentic harness is the body around the model, context engineering is the discipline of feeding that body the right information at the right time.
It has quietly become the most important skill in building AI systems that actually work. A large language model is only as good as what it can see when it answers. Give it the wrong context, too much context, or context in the wrong order, and even the most capable model produces confused, generic, or wrong results. Get the context right, and an average model can perform like an expert.
From prompt engineering to context engineering
For the first wave of generative AI, the craft was prompt engineering: writing the single, well-worded instruction that coaxed the best answer out of a model. That still matters, but it describes a one-shot conversation.
Modern AI systems, especially agents, are different. They run over many steps, pull in documents, call tools, and accumulate history. The question is no longer “what is the perfect sentence to type?” but “what is the complete set of information the model should have in front of it for this step, and what should we leave out?” That broader, systemic question is context engineering. Prompt engineering is one part of it; context engineering is the whole picture.
Why the context window is the constraint
Every model has a context window: a hard limit on how much information it can consider at once, measured in tokens. Windows have grown large, but three realities make “just put everything in” a losing strategy:
- Cost and latency. More tokens mean higher cost and slower responses on every single call.
- Context rot. As a window fills, models reliably get worse at finding and using any one fact buried inside it. More information can mean worse answers.
- Attention is finite. A model spreads its focus across everything you give it. Irrelevant material doesn’t just waste space; it actively distracts the model from what matters.
The context window is a scarce, expensive resource. Context engineering is how you spend it wisely.
What goes into the window
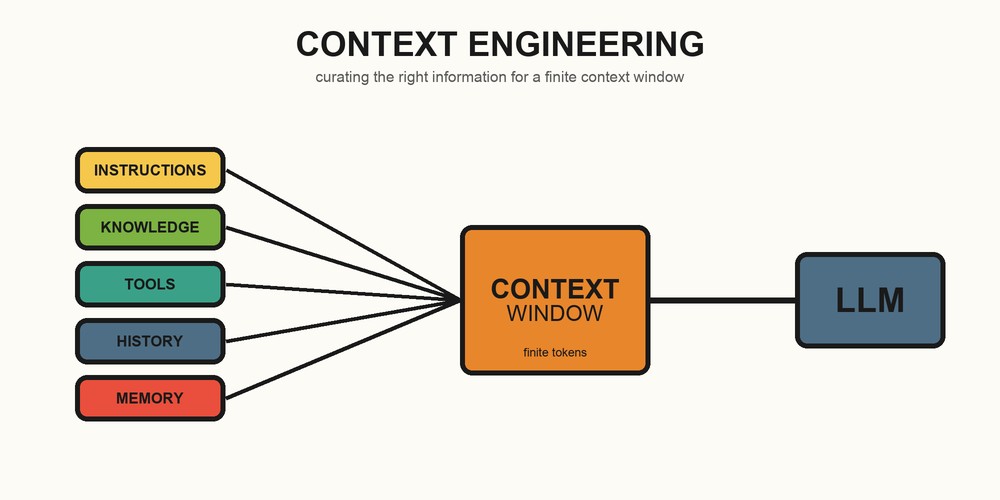
A useful way to think about context is as a budget you allocate across competing sources:
- Instructions – the system prompt, role, rules, and output format.
- Knowledge – facts retrieved from your documents, databases, or the web for this specific task (often via retrieval-augmented generation, or RAG).
- Tools – the definitions and results of any functions the model can call.
- History – the relevant parts of the conversation or task so far.
- Memory – durable facts about the user or prior work, carried across sessions.
Every token spent on one source is a token not available to another. Context engineering is the ongoing act of balancing that budget for each step of the task.
The core techniques
Practitioners rely on a handful of repeatable moves:
- Select (retrieve). Pull in only the most relevant documents or facts, rather than everything you have. Good retrieval is the engine of accurate, grounded answers.
- Compress. Summarize long histories and large documents so their meaning survives while their token count shrinks. Long-running agents lean heavily on summarization to keep going.
- Order. Place the most important information where the model attends best, typically near the beginning and the end. Burying the key fact in the middle is a common, avoidable mistake.
- Format. Structure the context clearly with headings, labels, and consistent markup. A model reads a well-organized context far better than a wall of text.
- Isolate. Split complex work across sub-agents or separate steps, each with its own clean, focused context, instead of cramming everything into one window.
Common failure modes
Naming the ways context goes wrong makes them easier to prevent:
- Distraction – so much extra material that the model loses the thread.
- Poisoning – a wrong or hallucinated fact enters the context early and contaminates every step that follows.
- Clashing – contradictory information in the window leaves the model unsure which to trust.
- Staleness – outdated context that no longer reflects the current state of the task or data.
Most disappointing agent behavior traces back to one of these, not to a weak model.
Why this matters for your business
Context engineering is where the practical value of AI is won or lost:
- Accuracy and trust come from grounding. An assistant that answers from your current, retrieved data is one customers can rely on. One that answers from the model’s stale general knowledge is a liability.
- Your edge lives in your context, not the model. Competitors can call the same models. What you connect to them, your proprietary documents, customer history, and domain knowledge, is what makes your AI distinctly yours.
- Cost scales with context. Disciplined context use directly lowers the per-interaction cost of running AI at scale.
- It is the highest-leverage place to improve. When an AI feature underperforms, reshaping its context usually helps faster and cheaper than swapping models.
The takeaway
As foundation models become a shared commodity, the differentiator shifts to how well you feed them. Context engineering, selecting, compressing, ordering, formatting, and isolating the right information for a finite window, is the skill that turns a capable model into a reliable, grounded, cost-effective system. Master it, and you give your AI exactly what it needs to help you drive differentiation, win clients, and grow your business.